Distributed key-value store indexing
Distributed key-value stores present an interesting alternative to some of the functionality relational databases are commonly employed for. Advantages include improved performance, easy replication, horizontal scaling and redundancy.
By nature, key value stores offer one way of retrieving data, by some sort of primary key which uniquely identifies each entry. But what about queries that require more elaborate input in order to collect relevant entries? Full text search engines like Sphinx and Lucence do exactly this and when used in conjunction with a database will query their indexes and return a collection of ids which are then used to retrieve the results from the database. Full text search engines support indexing data sources other than RDBMSs, so there's no reason why one couldn't index a distributed key-value store.
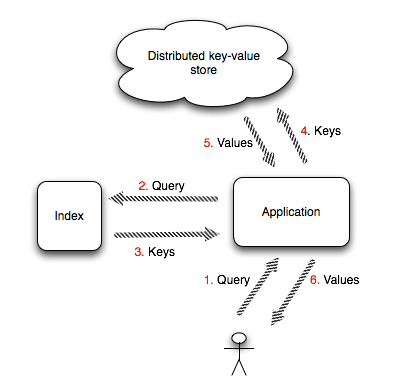
Here, we'll look at how we can integrate Sphinx with MemcacheDB, a distributed key-value store which conforms to the memcached protocol and uses Berkeley DB as its storage back-end.
Sphinx comes with an xmlpipe2 datasource, a generic XML interface aimed at simplifying custom integration. What this means is that our application can transform content from MemcacheDB into this format and feed it to Sphinx for indexing. The highlighted lines from the following Sphinx configuration instruct Sphinx to use the xmlpipe2 source type and invoke the ruby /app/lib/sphinxpipe.rb script in order to retrieve the data to index.
# sphinx.conf
source products_src
{
type = xmlpipe2
xmlpipe_command = ruby /app/lib/sphinxpipe.rb
}
index products
{
source = products_src
path = /app/sphinx/data/products
docinfo = extern
mlock = 0
morphology = stem_en
min_word_len = 1
charset_type = utf-8
enable_star = 1
html_strip = 0
}
indexer
{
mem_limit = 256M
}
searchd
{
port = 3312
log = /app/sphinx/log/searchd.log
query_log = /app/sphinx/log/query.log
read_timeout = 5
max_children = 30
pid_file = /app/sphinx/searchd.pid
max_matches = 10000
seamless_rotate = 1
preopen_indexes = 0
unlink_old = 1
}
Following is a Product class. Each product instance can present itself as xmlpipe2 data. The class itself gets the entire product catalog as a xmlpipe2 data source. It also has a search method used for querying Sphinx and retrieving matched products from MemcacheDB. Finally, there's a bootstrap method for populating the store with some example data.
# product.rb
require "rubygems"
require "xml/libxml"
require "memcached"
require "riddle"
class Product
attr_reader :id
MEM = Memcached.new('localhost:21201')
def initialize(id, title)
@id, @title = id, title
end
def to_sphinx_doc
sphinx_document = XML::Node.new('sphinx:document')
sphinx_document['id'] = @id
sphinx_document << title = XML::Node.new('title')
title << @title
sphinx_document
end
# Query sphinx and load products with matched ids from MemcacheDB
def self.search(query)
client = Riddle::Client.new
client.match_mode = :any
client.max_matches = 10_000
results = client.query(query, 'products')
ids = results[:matches].map {|m| m[:doc].to_s}
MEM.get(ids) if ids.any?
end
# Load all products from MemcacheDB and convert them to xmlpipe2 data
def self.sphinx_datasource
docset = XML::Document.new.root = XML::Node.new("sphinx:docset")
docset << sphinx_schema = XML::Node.new("sphinx:schema")
sphinx_schema << sphinx_field = XML::Node.new('sphinx:field')
sphinx_field['name'] = 'title'
keys = MEM.get('product_keys')
products = MEM.get(keys)
products.each { |id, product| docset << product.to_sphinx_doc }
%(<?xml version="1.0" encoding="utf-8"?>\n#{docset})
end
# Create a some products and store them in MemcacheDB
def self.bootstrap
product_ids = ('1'..'5').to_a.inject([]) do |ids, id|
product = Product.new(id, "product #{id}")
MEM.set(product.id, product)
ids << id
end
MEM.set('product_keys', product_ids)
end
end
The sphinxpipe.rb script looks like this.
# sphinxpipe.rb Product.bootstrap puts Product.sphinx_datasource
With MemcacheDB (or even memcached for the purpose of this example) running, we can tell Sphinx to create an index of products by invoking indexer --all -c sphinx.conf and then start the search daemon - searchd -c sphinx.conf. Now we're ready to start querying the index and retrieving results from the distributed store.
puts Product.search('product 1').inspect
It is not uncommon for the database to become a performance hotspot. The integration of a fast, distributed key-value store with an efficient search engine can be an interesting substitute for high throughput data retrieval operations.